Developer Documentation
# Let's Data : Focus on the data - we'll manage the infrastructure!
Cloud infrastructure that simplifies how you process, analyze and transform data.
Billing
#Let's Data charges are usage based - there are no upfront fees, hidden costs, recurring charges or service minimums.
As the datasets execute, their resource usage is calculated, costed and added to the customer's invoice. The invoice is charged at the end of the billing cycle.
Cost Types
Datasets execution causes #Let's Data to initialize a variety of different AWS resources - these include the write connector (e.g. kinesis stream), the error connectors (e.g. S3 bucket) and different internal components such as queues, database tables, compute resources etc.
These resources start accruing costs as soon as they are created. The costs can be classified into two categories: 1./ Use-time cost 2./ Recurring costs
- Use-Time Costs: Use-time costs are costs that accrue when the resources are being used. If the resources are not being used, these costs do not add up. For example, Lambda compute duration costs only for the time the lambda function was running. If the function is not running, there would be no costs. Similar examples are Requests per second, Bytes Transferred per second etc.
- Recurring Costs: Recurring costs are costs that keep on adding up as long as the resource remains initialized. For example, a kinesis stream's Shard-hours costs are such an example - every hour the kinesis shards size is calculated and costed. Even if the dataset is complete and no data is being written / read from the kinesis stream, the Shard-hours costs keep adding up. Similar examples are S3 Bucket Storage Bytes, Dynamo DB Storage Bytes etc.
Usage Types and Pricing
The service usages are charged for the connectors, compute engine and system's internal resources for a dataset execution along with their pricing.
Connectors
The different read, write and error connectors are charged as follows:
Compute Engine
The different compute engines are charged as follows:
System's Internal Usage
System's internal usage is charged along the following dimensions:
Caveat
While the upside of this pricing / billing approach is that it maps to AWS usage types and services - so it is easy to understand for the user. However, we do know this does complicate cost calculations for the user. How much will my dataset cost? As we get more data samples around billing and dataset costs, we are hoping to simplify this into a single dataset billing metric (or a few billing metrics) so that cost calculations for datasets are tenable. (We'd love any suggestions around this as well - what works and what doesnt work)
Invoicing
- For each dataset execution by the customer, we calculate the usage of different resources involved in the dataset execution.
- These usage records are then costed and added to the customer invoice.
- At the end of the billing cycle (monthly), the customer invoice is finalized and the customer card on file is charged with the invoice amount.
- Every invoice is emailed to the customer on finalization and the customers can also view the invoices anytime on the #Let's Data website.
- We also publish detailed, granular records of each service's usage records for each dataset. These are viewable on the dataset page and the via the CLI.
Usage Records
Here are the schema and example Usage Records that are emitted by #Let's Data.Users can use the following commands to retrieve usage and cost information:
Cost Management
Considering that our datasets are active for a finite amount of time, it makes sense to reclaim any resources that were initialized for the dataset processing but are not being used anymore since the dataset has COMPLETED /ERRORED. A notable exception to these is data in the write connectors / error connectors that may still be used by the external applications. If these unused resources are not reclaimed, they can easily add up to the costs for the dataset and result in a larger than expected billed amount.
With this reasoning in mind, we've architected the dataset execution and resource management to be optimized for costs - we try and determine if the dataset execution is complete (and would not require any reruns) and attempt to descale / freeze the resources that were associated with the dataset. These cost management actions (descale, freeze and delete) are also available to the user to descale / freeze / delete datasets using their own custom logic if needed.
Here is the cost management section from the dataset lifecycle diagram:
Here are what each of these cost management actions mean:
- DESCALED: This is when dataset has completed processing (success or error) and user / cost management service has decided to descale (different from reclaimed) the resources that were allocated for the dataset. For example, provisioned throughputs are decreased, lambda concurrency reclaimed etc. Though not supported yet, but dataset in this state can have its resources re-hydrated to rerun tasks etc if needed.
- FROZEN: This is when the dataset has completed processing and the user / cost management service has decided to reclaim the resources that were allocated for the dataset. For example, internal queues are deleted, processing tables are deleted and any non user data infrastructure is reclaimed. Things such as user data in write destination and error destinations are still available though - this means that the dataset is essentially read-only and dataset consumers can continue processing from a frozen dataset. A frozen dataset cannot be re-hydrated.
- DELETED: This is when the user has decided to delete the dataset - all resources are reclaimed. Zombie records are kept to disallow recreation and aid delayed processes such as billing etc.
See Cost Management Docs for additional details around cost optimizations
Updating Payment Details
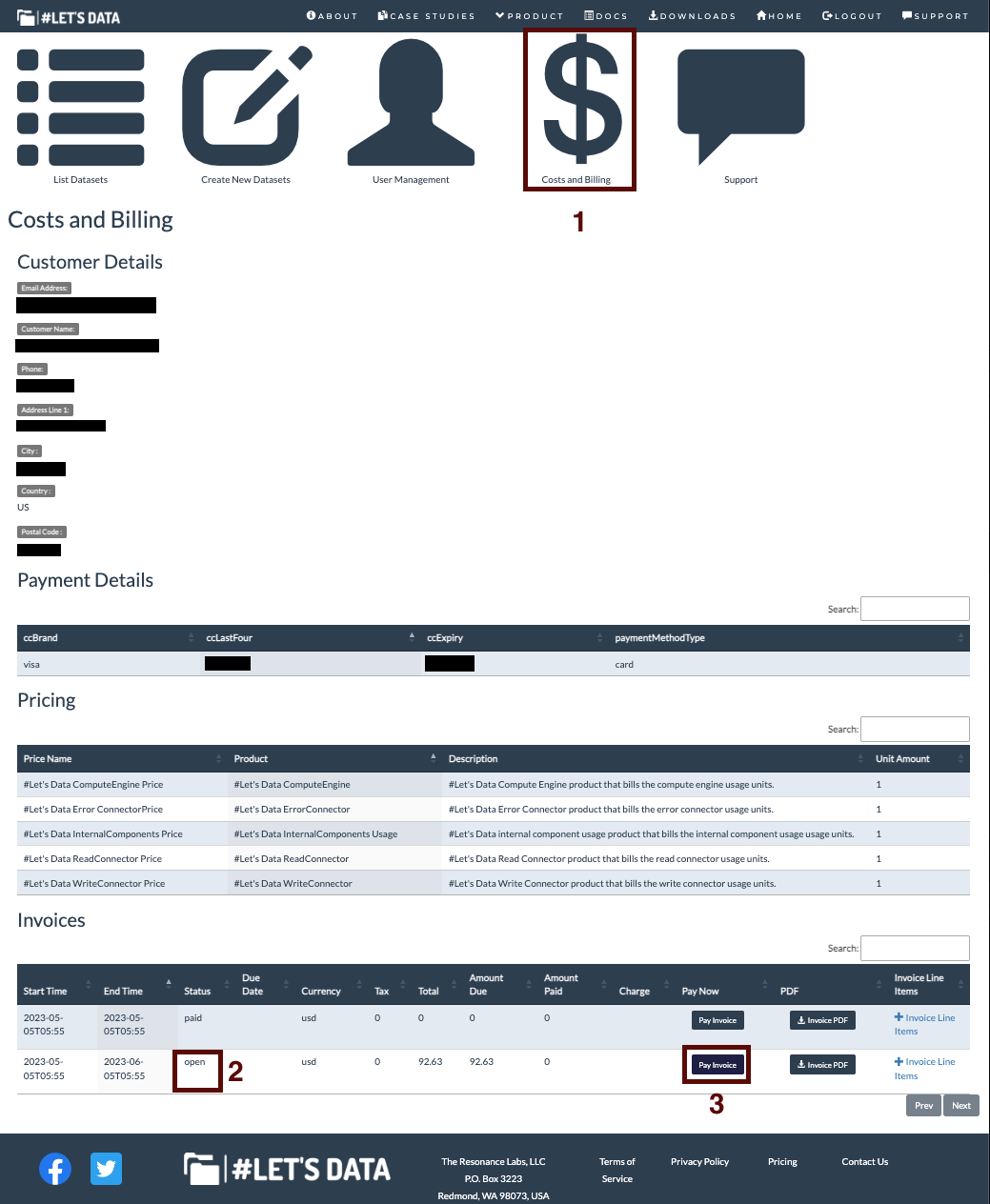
To update payment details and pay a pending invoice, follow these steps:
- Login to the #Let's Data Console Home
- Navigate to the "Costs And Billing" section, locate the unpaid invoice and click the Pay invoice button
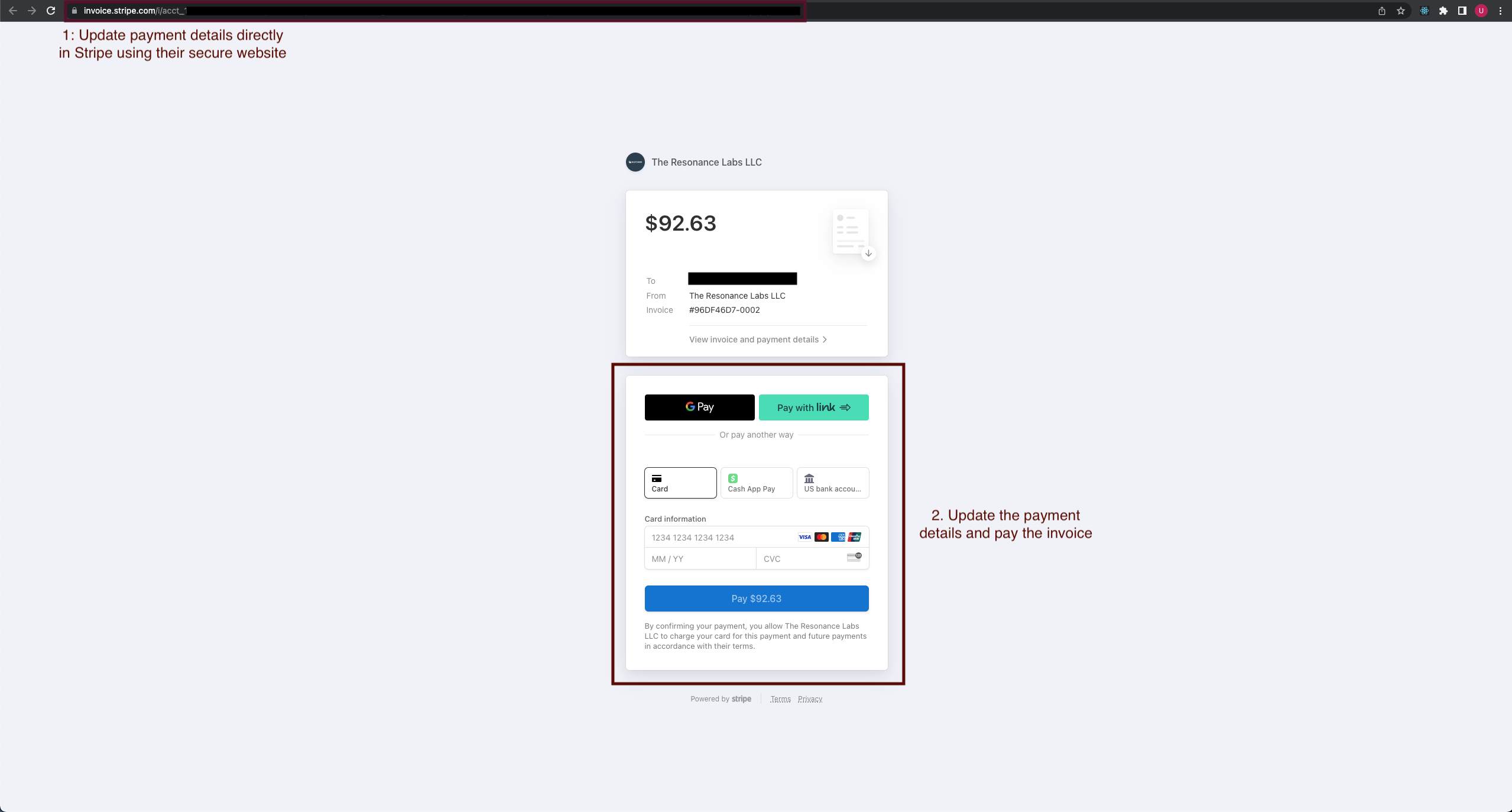
- This will redirect you to the invoice payment page hosted on Stripe. Update your payment details directly in stripe using their secure website and then pay the invoice.
The Resonance Labs, LLC
P.O. Box 3223
Redmond, WA 98073, USA